Francesco and Andrea have asked me to join them in doing a short course before the conference of the Italian Health Economics Association (AIES). The course is about Bayesian statistics and health economics and will be in Rome on November 14th.
I think we have quite a lot to cover and whether we'll actually manage to do everything depends on how people are familiar with Bayesian statistics. But potentially we can talk about quite a few interesting things, including how to do Bayesian statistics in health economics. I think I'll show at least some of the problems from the book, but there's no lab, which is a shame.
On second thoughts, however, if they had their computer to do the exercises, then we'd definitely not going to make it on time, so probably it's just as well...
Wednesday 31 October 2012
Cox & Mayo

To me, and I know this is veeeeery mature of me, this has the same comic effect of when I first read a paper by David Cox and Deborah Mayo. These two are of course serious people, doing amazing work in their respective fields (of course, statistics for Sir David; and philosophy of science for Deborah Mayo). But, then again, as Sheldon Cooper, PhD would put it: "what's life without whimsy?"
Anyway, I've had a bit of Cox & Mayo this week; first, I've seen this post on Christian Robert's blog, in which he discusses some of Mayo's position on Bayesian statistics. Mayo works in the field of philosophy of science and is a proposer of the frequentist approach. In fact, as Christian also mentions, her position is quite critical of the Bayesian approach and I too have noticed (although I have to say I have not read as much of her work) that she has a sort of "military resistance" attitude to it.
Perhaps in philosophy of science there is a presumption that only the Bayesian approach has philosophically sound foundations; I can see that we Bayesians may sometimes see ourselves as the "righteous ones" (mainly because we are $-$ only kidding, of course), although I think this probably was a real issue quite a while back; certainly not any more, at least from where I stand.
If this is indeed the case, maybe her position is justifiable and she serves the purpose of keeping a balanced perspective in the field. In my very limited experience and interaction with that environment, I've been lucky enough to talk quite a few times with people like Hasok Chang (who at some point was my joint boss) and Donald Gillies. The impression I had was that there was no perception that from the philosophical point of view, "most of Statistics is under threat of being overcome (or “inundated”) by the Bayesian perspective" (as Christian put it). I really liked Christian's post and essentially agreed on all accounts.
The second part of this story is about this morning's lecture by David Cox (which was organised by Bianca and Rhian). He talked about the principles of statistics, in what he said was a condensed version of a 5-hours lecture. Of course, it was interesting. He's a very good speaker and it's amazing to see how energetic he still is (he's 88 $-$ I was about to complain that my back is hurting today, but that put me in perspective!).
There were a few points I quite liked and a few more I quite didn't. First, I liked that he slipped in an example in which he implicitly said he's an Aston Villa fan; now I feel justified about putting a bit about Sampdoria in chapter 2 of the book $-$ I can always said I did it like Cox, which to a statistician is quite something...
Also, I liked the distinction he made between what he called "phenomenological" and "substantive" models. The first term indicates all those models that are general enough to be widely applicable (including, as he put it "those strange models that people use to analyse survival data"), but not directly related to the science underlying the problem at hand. Something like: you can "always" use regression analysis, and effectively the same formulation can apply to medicine, agriculture or social science. The maths behind the model is the same. The second term indicates models that are specifically built to describe a specific bit of science; they are thus very much specific, although of course you may not be able to apply them in many cases. A bit like decision models (as opposed to individual data models) in health economics.
What I didn't quite like (but that was to be expected) was his take on Bayesian statistics, and specifically on the subjective/personalistic approach. I think I've heard him talk about it on another occasion, and that time it was even worse (from my Bayesian perspective), but the point is that he basically said that there's no room for such an approach in science, with which I respectfully (but totally) disagree. In fact, as Tom pointed out while we were walking back, at some point he was even a bit contradictory when he framed the significance of RCTs data in terms of the problem a doctor faces when deciding what's the best course of action for the next patient $-$ pretty much a personalistic decision problem!
Monday 29 October 2012
More football
Given that Sampdoria have lost their fourth game in a row, I am not really interested in football any more (as of yesterday, I actually find it a very boring game and think we should focus on real sports $-$ of course if we manage to break the crappy run, I'll be back to liking it...). But, because Kees has done some more work using R2jags (here and here $-$ I've actually only seen this morning, although I think some of it at least is from a couple weeks back), I thought I would spend a few minutes on football anyway.
In the first, he's modified his original model and (I guess) linked to our formulation; in his new Bayesian model, he specifies the number of goals scored by the two competing teams as Poisson variables; the log-linear predictor is then specified depending on the "home-effect", the attack strength for that team and the defence strength of the opponents.
In our formulation, the attack and defence effects were modelled as exchangeable, which induced correlation among the different teams and therefore between the two observed variables. Kees uses a slightly different model where they both depend on an "overall" strength for each team (modelled as exchangeable) plus another exchangeable, team-specific "attack/defence balance" effect.
This is interesting, but the main problem seems to remain the fact that you tend to see clear mixtures of effects (ie "bad" teams having quite different behaviour from "good" teams); he tried to then use the mix module in JAGS to directly model the effects as mixtures of exchangeable Normal distributions, but seems to have run in some problems.
We did it slightly differently (ie using informative priors on the chance each team belongs to one of three categories: "top" teams; "strugglers"; and "average" teams). We only run it in BUGS, but because of our specification, we didn't have problems with convergence or the interpretation (only slightly slower). I've not tried the JAGS version with the mix module (I suppose we should fiddle a bit with the original code $-$ which is here, by the way, is someone has time/interest in doing so). But it shouldn't be a problem, I would think.
In Kees model, he needs to fix some of the effects to avoid convergence and identifiability issues, if I understand it correctly. Marta and I had always wanted to explore the mixture issue further, but never got around to have time to actually do it. If I only I could like football again...
In the first, he's modified his original model and (I guess) linked to our formulation; in his new Bayesian model, he specifies the number of goals scored by the two competing teams as Poisson variables; the log-linear predictor is then specified depending on the "home-effect", the attack strength for that team and the defence strength of the opponents.
In our formulation, the attack and defence effects were modelled as exchangeable, which induced correlation among the different teams and therefore between the two observed variables. Kees uses a slightly different model where they both depend on an "overall" strength for each team (modelled as exchangeable) plus another exchangeable, team-specific "attack/defence balance" effect.
This is interesting, but the main problem seems to remain the fact that you tend to see clear mixtures of effects (ie "bad" teams having quite different behaviour from "good" teams); he tried to then use the mix module in JAGS to directly model the effects as mixtures of exchangeable Normal distributions, but seems to have run in some problems.
We did it slightly differently (ie using informative priors on the chance each team belongs to one of three categories: "top" teams; "strugglers"; and "average" teams). We only run it in BUGS, but because of our specification, we didn't have problems with convergence or the interpretation (only slightly slower). I've not tried the JAGS version with the mix module (I suppose we should fiddle a bit with the original code $-$ which is here, by the way, is someone has time/interest in doing so). But it shouldn't be a problem, I would think.
In Kees model, he needs to fix some of the effects to avoid convergence and identifiability issues, if I understand it correctly. Marta and I had always wanted to explore the mixture issue further, but never got around to have time to actually do it. If I only I could like football again...
Thursday 25 October 2012
Ben pharma
Quite regularly, Marta comes up with some idea to reshuffle something around the house (eg move furniture around, or change the way things are). Normally, mostly because I am a bit lazy, but sometimes because I genuinely don't really see the point, my reaction is to find a logical and rational explanation to why we shouldn't do it. Most of the times, I miserably fail to do so and then we do whatever she plans (in fact, even if I manage to find a reason not to, usually the best I can get is to delay the implementation of the Marta-policy).
At the weekend I ran out of excuses not to move the furniture in the living room (with subsequent ebay bonanza of most of the stuff we have to make way for new exciting things) and so I capitulated. Previously, we had the TV in the top-right corner of the room, with a sofa facing it and an armchair (which I normally sit on) to its left. The new version of the room has the TV in the top-left corner with the armchair now facing it and the sofa to its right.
Obviously, neither I nor the cat liked the changes at first, but the worst thing is that now the two of us are fighting over who gets to sit on the armchair (before, he would sit on the sofa $-$ evidently, like Sheldon Cooper PhD, he just loves that spot). So now, while I sit on (allegedly) my armchair watching telly, or reading my book, I also have to deal with him, patiently looking for his way in to jump on the chair and start pushing me away.
Anyway: the book I'm reading at the moment is Bad Pharma by Ben Goldacre (I've already briefly mentioned it here). It's interesting and I agree with quite a lot that he's arguing. For example, he rants about the fact that trials are often "hidden" by pharmaceutical companies who don't want "unflattering evidence" about their products out for researchers, patients and clinicians to see. This obviously makes like complicated when one tries to put all the evidence in perspective (given that one doesn't have all the evidence to work with...).
But, I have to say (and I'm only in about 100 pages, so just about 1/4 of the book), I don't quite like some of the things he says, or rather the way in which he says them. It seems to me that the underlying assumption is that there is some absolute truth out there (in this case about whether drugs work or not, or have side effects, etc). The problem is that people either hide some evidence, or use biased methods to analyse their data.
For instance, there is an example about a study on duloxetine, in which the industry-led research used last observation carried forward in their analysis. Now, of course we know that this is not ideal and opens up the possibility of crucial bias in the results. But, as far as I'm aware, dealing with missing data is much an art as is a science and there are all sorts of untestable assumptions that have to be included in the model, even when you use a better, more robust, more accepted one. I think this consideration is missing (or at least not clear enough) in Ben's discussion.
I'm not quite of the persuasion that life is 0/1; wrong/correct; all/nothing. To me, the objective of statistical analysis is not to provide facts, but rather to quantify uncertainty. As Lindley puts it, uncertainty is a fact of life, and we just have to deal with it. And statistical modelling is hardly something that goes without uncertainty. Yes we all use Cox's model for survival data, or logistic regression for binary outcomes; but who's to say (in general) that these are the only good ways of modelling these kind of data?
I think that Andrew Gelman makes this point quite often, when he defends Bayesian models vs frequentist ones. Often people tend to criticise the choice of priors, while the data model is considered as an uncontroversial piece of the model, but I agree with Gelman that the prior is only one side of the story. Christian Robert has an interesting post on his blog, in which he quotes a professor of Astrophysics discussing about the role of stats in science.
Anyway, as I said, other than this aspect, I agree with Ben's general message and I'll keep reading the book.
By the way: the living room does look better in its new version.
At the weekend I ran out of excuses not to move the furniture in the living room (with subsequent ebay bonanza of most of the stuff we have to make way for new exciting things) and so I capitulated. Previously, we had the TV in the top-right corner of the room, with a sofa facing it and an armchair (which I normally sit on) to its left. The new version of the room has the TV in the top-left corner with the armchair now facing it and the sofa to its right.
Obviously, neither I nor the cat liked the changes at first, but the worst thing is that now the two of us are fighting over who gets to sit on the armchair (before, he would sit on the sofa $-$ evidently, like Sheldon Cooper PhD, he just loves that spot). So now, while I sit on (allegedly) my armchair watching telly, or reading my book, I also have to deal with him, patiently looking for his way in to jump on the chair and start pushing me away.
Anyway: the book I'm reading at the moment is Bad Pharma by Ben Goldacre (I've already briefly mentioned it here). It's interesting and I agree with quite a lot that he's arguing. For example, he rants about the fact that trials are often "hidden" by pharmaceutical companies who don't want "unflattering evidence" about their products out for researchers, patients and clinicians to see. This obviously makes like complicated when one tries to put all the evidence in perspective (given that one doesn't have all the evidence to work with...).
But, I have to say (and I'm only in about 100 pages, so just about 1/4 of the book), I don't quite like some of the things he says, or rather the way in which he says them. It seems to me that the underlying assumption is that there is some absolute truth out there (in this case about whether drugs work or not, or have side effects, etc). The problem is that people either hide some evidence, or use biased methods to analyse their data.
For instance, there is an example about a study on duloxetine, in which the industry-led research used last observation carried forward in their analysis. Now, of course we know that this is not ideal and opens up the possibility of crucial bias in the results. But, as far as I'm aware, dealing with missing data is much an art as is a science and there are all sorts of untestable assumptions that have to be included in the model, even when you use a better, more robust, more accepted one. I think this consideration is missing (or at least not clear enough) in Ben's discussion.
I'm not quite of the persuasion that life is 0/1; wrong/correct; all/nothing. To me, the objective of statistical analysis is not to provide facts, but rather to quantify uncertainty. As Lindley puts it, uncertainty is a fact of life, and we just have to deal with it. And statistical modelling is hardly something that goes without uncertainty. Yes we all use Cox's model for survival data, or logistic regression for binary outcomes; but who's to say (in general) that these are the only good ways of modelling these kind of data?
I think that Andrew Gelman makes this point quite often, when he defends Bayesian models vs frequentist ones. Often people tend to criticise the choice of priors, while the data model is considered as an uncontroversial piece of the model, but I agree with Gelman that the prior is only one side of the story. Christian Robert has an interesting post on his blog, in which he quotes a professor of Astrophysics discussing about the role of stats in science.
Anyway, as I said, other than this aspect, I agree with Ben's general message and I'll keep reading the book.
By the way: the living room does look better in its new version.
Tuesday 23 October 2012
Bayes for President!
I couldn't resist getting sucked into the hype associated with the US election and debates, and so I thought I had a little fun of my own and played around a bit with the numbers. [OK: you may disagree with the definition of "fun" $-$ but then again, if you're reading this you probably don't...]
So, I looked on the internet to find reasonable data on the polls. Of course there are a lot of limitations to this strategy. First, I've not bothered doing some sort of proper evidence synthesis, taking into account the different polls and pooling them in a suitable way. There are two reasons why I didn't: the first one is that not all the data are publicly available (as far as I can tell), so you have to make do with what you can find; second, I did find some info here, which seems to have accounted for this issue anyway. In particular, this website contains some sort of pooled estimates for the proportion of people who are likely to vote for either candidate, by state, together with a "confidence" measure (more on this later). Because not all the states have data, I have also looked here and found some additional info.
Leaving aside representativeness issues (which I'm assuming are not a problem, but may well be, if this were a real analysis!), the second limitation is of course that voting intentions may not directly translate into actual votes. I suppose there are some studies out there to quantify this, but again, I'm making life (too) easy and discount this effect.
The data on the polls that I have collected in a single spreadsheet look like this
ID State Dem Rep State_Name Voters Confidence
1 AK 38 62 Alaska 3 99.9999
2 AL 36 54 Alabama 9 99.9999
3 AR 35 56 Arkansas 6 99.9999
4 AZ 44 52 Arizona 11 99.9999
5 CA 53 38 California 55 99.9999
... ... ... ... ...
Using this bit of code, one can estimate the parameters of a Beta distribution centered on the point estimate and for which the probability of exceeding the threshold 0.5 is given by the level of confidence.
The function betaPar2 has several outputs, but the main ones are res1 and res2, which store the values of the parameters $\alpha$ and $\beta$, which define the suitable Beta distribution. In fact, the way I'm modelling is to say that if the point estimate is below 0.5 (a state $s$ where Romney is more likely to win), then I want to derive a suitable pair $(\alpha_s,\beta_s)$ so that the resulting Beta distribution is centered on $m_s$ and for which the probability of not exceeding 0.5 is given by $c_s$ (which is defined as the level of confidence for state $s$, reproportioned in [0;1]). However, for states in which Obama is more likely to win ($m_s\geq 0.5$), I basically do it the other way around (ie working with 1$-m_s$). In these cases, the correct Beta distribution has the two parameters swapped (notice that I assign the element res2 to $\alpha_s$ and the element res1 to $\beta_s$).

In line with the information from the polls, the estimated average proportion of Democratic votes is around 38% and effectively there's no chance of Obama getting a share that is greater than 50%.


So, I looked on the internet to find reasonable data on the polls. Of course there are a lot of limitations to this strategy. First, I've not bothered doing some sort of proper evidence synthesis, taking into account the different polls and pooling them in a suitable way. There are two reasons why I didn't: the first one is that not all the data are publicly available (as far as I can tell), so you have to make do with what you can find; second, I did find some info here, which seems to have accounted for this issue anyway. In particular, this website contains some sort of pooled estimates for the proportion of people who are likely to vote for either candidate, by state, together with a "confidence" measure (more on this later). Because not all the states have data, I have also looked here and found some additional info.
Leaving aside representativeness issues (which I'm assuming are not a problem, but may well be, if this were a real analysis!), the second limitation is of course that voting intentions may not directly translate into actual votes. I suppose there are some studies out there to quantify this, but again, I'm making life (too) easy and discount this effect.
The data on the polls that I have collected in a single spreadsheet look like this
ID State Dem Rep State_Name Voters Confidence
1 AK 38 62 Alaska 3 99.9999
2 AL 36 54 Alabama 9 99.9999
3 AR 35 56 Arkansas 6 99.9999
4 AZ 44 52 Arizona 11 99.9999
5 CA 53 38 California 55 99.9999
... ... ... ... ...
The columns Dem and Rep represent the pooled estimation of the proportion of voters for the two main parties (of course, they may not sum to 100%, due to other possible minor candidates or undecided voters). The column labelled Voters gives the number of Electoral Votes (EVs) in each state (eg if you win at least 50% of the votes in Alaska, this is associated with 3 votes overall, etc). Finally, the column Confidence indicates the level of (lack of) uncertainty associated with the estimation. States with high confidence are "nearly certain" $-$ for example, the 62% estimated for Republicans in Alaska is associated with a very, very low uncertainty (according to the polls and expert opinions). In most states, the polls are (assumed to be) quite informative, but there are some where the situation is not so clear cut.
I've saved the data in a file, which can be imported in R using the command
polls <- read.csv("http://www.statistica.it/gianluca/Polls.csv")
At this point, I need to compute the 2-party share for each state (which I'm calling $m$) and fix the number of states at 51
attach(polls)
m <- Dem/(Dem+Rep)
Nstates <- 51
Now, in truth this is not a "proper" Bayesian model, since I'm only assuming informative priors (which are supposed to reflect all the available knowledge on the proportion of voters, without any additional observed data). Thus, all I'm doing is a relatively easy analysis. The idea is to first define a suitable informative prior distribution based on the point estimation of the democratic share and with uncertainty defined in terms of the confidence level. Then I can use Monte Carlo simulations to produce a large number of "possible futures"; in each future and for each state, the Democrats will have an estimated share of the popular vote. If that is greater than 50%, Obama will have won that state and the associated EVs. I can then use the induced predictive distribution on the number of EVs to assess the uncertainty underlying an Obama win (given that at least 272 votes are necessary to become president).
In their book, Christensen et al show a simple way of deriving a Beta distribution based on an estimation of the mode, an upper limit and a confidence level that the variable is below that upper threshold. I've coded this in a function betaPar2, which I've made available from here (so you need to download it, if you want to replicate this exercise).
Using this bit of code, one can estimate the parameters of a Beta distribution centered on the point estimate and for which the probability of exceeding the threshold 0.5 is given by the level of confidence.
a <- b <- numeric()
for (s in 1:Nstates) {
if (m[s] < .5) {
bp <- betaPar2(m[s],.499999,Confidence[s]/100)
a[s] <- bp$res1
b[i] <- bp$res2
}
if (m[s] >=.5) {
bp <- betaPar2(1-m[s],.499999,Confidence[s]/100)
a[s] <- bp$res2
b[s] <- bp$res1
}
}
The function betaPar2 has several outputs, but the main ones are res1 and res2, which store the values of the parameters $\alpha$ and $\beta$, which define the suitable Beta distribution. In fact, the way I'm modelling is to say that if the point estimate is below 0.5 (a state $s$ where Romney is more likely to win), then I want to derive a suitable pair $(\alpha_s,\beta_s)$ so that the resulting Beta distribution is centered on $m_s$ and for which the probability of not exceeding 0.5 is given by $c_s$ (which is defined as the level of confidence for state $s$, reproportioned in [0;1]). However, for states in which Obama is more likely to win ($m_s\geq 0.5$), I basically do it the other way around (ie working with 1$-m_s$). In these cases, the correct Beta distribution has the two parameters swapped (notice that I assign the element res2 to $\alpha_s$ and the element res1 to $\beta_s$).
For example, for Alaska (the first state), the result is an informative prior like this.

In line with the information from the polls, the estimated average proportion of Democratic votes is around 38% and effectively there's no chance of Obama getting a share that is greater than 50%.
Now, I can simulate the $n_{\rm{sims}}=10000$ "futures", based on the uncertainty underlying the estimations using the code
nsims <- 10000
prop.dem <- matrix(NA,nsims,Nstates)
for (i in 1:Nstates) {
prop.dem[,i] <- rbeta(nsims,a[i],b[i])
}
The matrix prop.dem has 10000 rows (possible futures) and 51 columns (one for each state).
I can use the package coefplot2 and produce a nice summary graph
library(coefplot2)
means <- apply(prop.dem,2,mean)
sds <- apply(prop.dem,2,sd)
low <- means-2*sds
upp <- means+2*sds
reps <- which(upp<.5) # definitely republican states
dems <- which(low>.5) # definitely democratic states
m.reps <- which(means<.5 & upp>.5) # most likely republican states
m.dems <- which(means>.5 & low<.5) # most likely democratic states
cols <- character()
cols[reps] <- "red"
cols[dems] <- "blue"
cols[m.reps] <- "lightcoral"
cols[m.dems] <- "deepskyblue"
vn <- paste(as.character(State)," (",Voters,")",sep="")
coefplot2(means,sds,varnames=vn,col.pts=cols,main="Predicted probability of democratic votes")
abline(v=.5,lty=2,lwd=2)
This gives me the following graph showing the point estimate (the dots), 95% and 50% credible intervals (the light and dark lines, respectively). Those in dark blue and bright red are the "definites" (ie those that are estimated to be definitely Obama or Romney states, respectively). Light blues and reds are those undecided (ie for which the credible intervals cross 0.5).

Finally, for each simulation, I can check that the estimated proportion of votes for the Democrats exceeds 0.5 and if so allocate the EVs to Obama, to produce a distribution of possible futures for this variable.
obama <- numeric()
for (i in 1:nsims) {
obama[i] <- (prop.dem[i,]>=.5)%*%Voters
}
hist(obama,30,main="Predicted number of Electoral Votes for Obama",xlab="",ylab="")
abline(v=270,col="dark grey",lty=1,lwd=3)

So, based on this (veeeeery simple and probably not-too-realistic!!) model, Obama has a pretty good chance of being re-elected. In almost all the simulations his share of the votes guarantees he gets at least the required 272 EVs $-$ in fact, in many possible scenarios he actually gets many more than that.
Well, I can only hope I'm not jinxing it!
Monday 22 October 2012
Thank you for smoking (and also doing take-away)

Then, finally, somebody figured out that smoking actually kills (for example, David Spiegelhalter said in his documentary that "two cigarettes cost half an hour". By the way, I thought that the documentary was good, but not great $-$ may be my expectations were too high...) and governments decided it was time to ban tobacco advertisements.
I guess I was too young when they actually did that across Europe, so I don' exactly remember what the public and industry reaction was $-$ I seem to remember I didn't really care; but then again, I've never being fascinated with smoking; plus, back then I was still convinced I'd end up playing for Sampdoria and overtaking Roberto Mancini as their best player ever...
Anyway, it all seems sensible: once we know (beyond any reasonable doubt and based on a series of scientific studies supporting each other) that something is a public health concern, then to limit its impact on the general population is the first thing a government should do, right?
Well, I'm not too sure: last week I saw this advert on TV. Apparently, there's this company that has a website which links together many take-away places, so all you need to do is give your postcode, select a type of food and choose your dinner from a wide range of menus.
So far, (almost) so good. I suppose that there are things that are not OK with take-away dinners: for example, probably they increase the level of pollution (eg plastic tupperwares, plastic/paper bags, car fuel, etc). Still, on the other hand, they can't be all bad and if someone did a full economic analysis then they should factor in possible benefits (eg reduced level of pollution due to the fact that you don't do the washing up afterwards?). And to be perfectly honest, I quite fancy the occasional take-away too.
But the advert I linked above really stretches it too far! I think they are meant to be funny and ironic in telling people that "The tyranny of home cooking has gone on for too long" and that "Cooking is burnt fingers; cooking is complicated recipes you need a PhD in Advanced Foodolgy to understand; cooking is celeb chef endorsed gadgets you buy and never use; cooking is hours in the kitchen to end up with mush that looks nothing like the recipe photo (and probably tastes like the paper the recipe was printed on)".
If anything, I think that the advert is in bad taste [see where I'm going with this one? Food, bad taste... Hilarious, isn't it? I won't be a professional footballer, but may be there's still hope for a stand up career?].
I think that there is a real danger that the message comes up as serious, rather than a funny (?) joke. And I don't think that's something we want $-$ if there are concerns about obesity as a serious public health concern, probably putting in people's mind that cooking is bad and you should only eat take-away dinners is probably not the smartest idea...
Now, I think the company should be allowed to market its product $-$ after all, everybody should be free to decide what to eat. But equally, doesn't the government have a duty to control over the way in which people are bombarded with adverts on how to live their lives?
Friday 19 October 2012
Badger calling

The very, very, very quick background to this story is that bovine tuberculosis (bTB) is an increasingly important problem; to put things in perspective, Christl said in her talk that over 26,000 cattle were compulsorily slaughtered after testing positive for the disease, last year. Clearly a huge problem in terms of animal welfare and, incidentally, for the British food industry.
I have to admit that I don't know enough to judge whether this is the only theory, or some other biological mechanism could be out there to explain things off. However, one theory (in fact, the theory, it appears) is that badgers living in and around farming areas are the main responsible for the epidemics of bTB. In the late 1990s, the government commissioned a study (which Christl led and described in her talk), to investigate whether "badger culling" (or, more appropriately, "killing"; that's effectively what it is...) would be effective in reducing the level of bTB. The study was complicated to even set up, but, as far as I understand, there is not much controversy on the high quality of the trial, which went on for nearly 10 years (and data are, in theory, continuously monitored $-$ apparently, DEFRA have changed their IT supplier, which has screwed things up and so the data for the last year are still not available).
The problem is that the results are not so clear cut as one would hope; according to Christl, badger culling seems to be effective within the "culling area", but also to produce higher rates of bTB just outside of it. Based on these results, the then Labour government didn't implement the policy; Tories and LibDems, on the other hand, were always in favour of culling and, once they happily got married in coalition government, they started plans to actually go for it.
But, and I'm coming to today's news, there is now an apparent U-turn, due to the high cost of implementation of the policy. In fact, in order to be effective, at least 70% of the badgers in a given area need to be culled; but because there was a very large uncertainty in the estimation of the badger population stocks, this has turned out to be a more complicated and expensive enterprise than expected (as the absolute numbers have gone up from previous estimations).
Now: to my mind this was always going to be a decision-making problem, where the cost components would play a major role. Christl said in her talk that, when they were setting up the trial and even later when presenting the results, some commentators pointed out that cost considerations should not enter the science, and they were criticised for actually taking them into account in their recommendations (in some way; I don't know the details here, but I'm guessing not in a formal, health-economics-like way). To me, this is nonsense and quite hypocritical too!
First, there's an underlying assumption that a cow is worth (considerably) more than a badger; if this weren't the case, then why killing an animal to save another one, instead of leaving Nature alone? Of course, to humans the value of a cow is quantifiable in terms of its market in the food industry, and thus is quite high. So, by definition of the problem, the very reason why the government bothered with the trial is economic. Second, if a policy is ever to be implemented, and if science is there to help decide the best course of action, how can the costs attached to a) gathering the relevant data; and b) eventually doing something not be relevant?
I think in this case the evidence is just not clear enough $-$ and that's not because of how the trial was run or the stats computed and presented. Things are just not clear. So perhaps the value of information (either on badger culling or implementing alternative or additional strategies) is clearly very high $-$ and possibly still affordable.
Wednesday 17 October 2012
Scotland don't leave us!
Last Saturday we went to the BBC to be part of the audience in a recording for a radio show. That's something we quite often do, since Marta discovered that you just need to apply and then you've got a pretty good chance of "winning" free tickets (especially for less known shows).
That's usually quite funny, especially when the show is for the radio (we went to TV shows a couple of times, but it's boring $-$ they have to look fancy and there are about a million re-takes at the end, during which you need to laugh at some joke you've already heard 2 or 3 times).
The show we saw on Saturday (Fringe Benefits) was a sort of summary of some of the best acts from the Edinburgh's Fringe Festival. Nearly all were quite good, but my favourite act of the night were Jonny and the Baptists, a trio mixing music and comedy.
They did this song about Scotland:
which I thought was quite funny. It's only fitting, of course, that a couple of days later the independence referendum deal was signed.
I'm not sure I know what to make of this; my gut feeling is that the Prime Minister Kirk Cameron (pun intended) has played a move that looks risky but it's probably not so much. I think that (much as for the Alternative Voting System referendum in 2011) they know very well that people tend to not show up for referenda, with average turnout well under 30% of the population who could in theory take part $-$ although in the last UK referendum, Scotland was the region with the highest turnout (just over 50%).
On the other hand, apparently the polls show that most Scottish people are not likely (for now) to vote for independence. This, I suppose, put the First Minister Alex Salmon (again, pun intended for par conditio) in a slightly uncomfortable situation: of course he couldn't say no to the opportunity of actually staging the referendum (by the way, at some point in the future $-$ although I don't know who'll decide exactly when). But he'll probably have to work hard to convince his fellow Scottish to go for independence.
That's usually quite funny, especially when the show is for the radio (we went to TV shows a couple of times, but it's boring $-$ they have to look fancy and there are about a million re-takes at the end, during which you need to laugh at some joke you've already heard 2 or 3 times).
The show we saw on Saturday (Fringe Benefits) was a sort of summary of some of the best acts from the Edinburgh's Fringe Festival. Nearly all were quite good, but my favourite act of the night were Jonny and the Baptists, a trio mixing music and comedy.
They did this song about Scotland:
which I thought was quite funny. It's only fitting, of course, that a couple of days later the independence referendum deal was signed.
I'm not sure I know what to make of this; my gut feeling is that the Prime Minister Kirk Cameron (pun intended) has played a move that looks risky but it's probably not so much. I think that (much as for the Alternative Voting System referendum in 2011) they know very well that people tend to not show up for referenda, with average turnout well under 30% of the population who could in theory take part $-$ although in the last UK referendum, Scotland was the region with the highest turnout (just over 50%).
On the other hand, apparently the polls show that most Scottish people are not likely (for now) to vote for independence. This, I suppose, put the First Minister Alex Salmon (again, pun intended for par conditio) in a slightly uncomfortable situation: of course he couldn't say no to the opportunity of actually staging the referendum (by the way, at some point in the future $-$ although I don't know who'll decide exactly when). But he'll probably have to work hard to convince his fellow Scottish to go for independence.
Thursday 11 October 2012
Willy Wonga & the money factory
The reason for this controversy is that the way they (are allowed to) work is to give easy and very quick loans, at amazing (for them!) rates. This is probably an old, outdated advert, but the idea is that they proudly roll with an "unrepresentative" 2012% APR.

Luckily, I'm not one to be too impress by TV adverts (normally I am able to just shut my brains down when they are on), but the first time I saw it I thought they've missed a "." and the rate was actually 20.12% or something. In fact, it looks as though their typical APR is twice as much (4,214%)!
Yet, they claim that their customers are very happy with the service (quoting satisfaction rates of over 90% $-$ see here). The interesting thing is how they are perceived (market themselves?) as a "data-driven" company. Their decision making process is based on evaluating a set of individual characteristics (for example, as the article in The Economist reports, "having a mobile phone with a contract helps to get money"). I thought this was how any bank would operate, but apparently start ups like Wonga do it in a better(?), more comprehensive way, eg combining different sources of information. I wonder what kind of algorithms they really have underlying their decision processes...
I suppose that the crucial point here is that with such high rates the expected value of information is really low; in other words, the uncertainty (risk) associated with each decision probably isn't really substantial (ie it does not have a real impact on the decision making process); because they lend small amounts of money, a customer defaulting is not too big a deal. But if the majority of customers can repay their debt (possibly lending more money), then they're (literally) golden...
Monday 8 October 2012
Laplace's liberation army

More to the point (to which I'm slowly but surely coming), if you google "inla" the first hit is the Irish national liberation army, again not quite what you'd expect (if you're a statistician with only limited interests outside your field, that is...).
But, speaking of INLA (I mean our INLA $-$ not the Irish separatists), Marta, Michela, Håvard and I have just finished our paper, reviewing its use for spatial and spatio-temporal Bayesian data analysis.
In comparison to the original series of INLA papers, we slightly changed the notation. Originally, Håvard and his co-authors had defined a linear predictor on (a suitable transformation of) the mean of the observed data as
$$ \eta_i = \alpha + \sum_{j=1}^{n_f}f^{(j)}(u_{ij}) \sum_{k=1}^{n_\beta} \beta_k z_{ki} + \epsilon_i, $$
and the parameters were defined as
$$\mathbf{x} = \left( \alpha,\{\beta_k\}, \{f^{(j)}(\cdot)\}, \{\epsilon_i\} \right) $$
and given a Gaussian Markov Random prior, as functions of a set of hyper-parameters $\boldsymbol\theta$.
I've always thought that this was a bit confusing, as we're normally used to thinking of $\boldsymbol\theta$ as "level-one" parameters and of $\mathbf{x}$ as observable covariates. In the paper, we've modified this to clarify (in my opinion) how this works; so for us $\boldsymbol\theta$ represents the set of parameters, while we use $\boldsymbol\phi$ for the hyper-parameters (ie the variances of the structured effects).
Also, in the original formulation, $\epsilon_i \sim \mbox{Normal} (0, \sigma_{\epsilon})$, with $\sigma_\epsilon \rightarrow 0$ is just a technical device used in the code to allow INLA to monitor directly the linear predictor $\eta_i$. But, as far as the model specification is concerned, there is no real need to include it (that's why we didn't).
In the paper there are also several worked examples (links to the data and the R code are available here).
What I should really blog about
I've just seen that, as of today (I think, given I haven't checked the blog over the weekend), this is the most read post in the blog. It has taken over from another post, which was also discussing football [digression: I realise that by linking to these post, I'm making them even slightly more likely to be read, but I think that the third most read is quite below their numbers, so it shouldn't really cause much bias].
Now, on the one hand this is kind of cool and actually should be guiding my future endeavours in terms of blogging, so that I can finally take over the web and become one of those people who go on telly and are presented as "bloggers":

On the other hand, however, it is a bit frustrating, considering that I try to be opinionated and write as-much-as-I-can-intelligent-stuff on topics that are (evidently, just supposed to be) a bit more important than football.
Well, may be before I abandon for ever everything else and focus my life on football only, I should consider that the real explanation is confounding, since the top post was also on R-blogger and thus it was probably exposed to a much wider audience than others.
Now, on the one hand this is kind of cool and actually should be guiding my future endeavours in terms of blogging, so that I can finally take over the web and become one of those people who go on telly and are presented as "bloggers":
On the other hand, however, it is a bit frustrating, considering that I try to be opinionated and write as-much-as-I-can-intelligent-stuff on topics that are (evidently, just supposed to be) a bit more important than football.
Well, may be before I abandon for ever everything else and focus my life on football only, I should consider that the real explanation is confounding, since the top post was also on R-blogger and thus it was probably exposed to a much wider audience than others.
Turin break

I used to like Turin Brakes in the early noughties; I also liked their name [digression: apparently, they didn't choose it because Turin was their favourite city (they hadn’t even been to Turin up to that point), or that they have brakes on their cars that originated from Turin (well they very well could have $–$ but that wasn’t the reason for the name). They just thought it sounded good. To me it was just a bit weird, but I liked it anyway...].
One thing I have in common with them is that I hadn't visited Turin until a couple of years ago (well, in fact I'm not sure they did too $-$ but you know what I mean...). Of course, in my case it's probably much worse, since I've lived for 20 odds years in Italy, so it really should have happened earlier.
However, since my first time, not only have I gone back in quite a few occasions, but I've also made some good friends who are, for one reason or another, related with Turin. Last week I went to give a talk at a conference and then I stayed over the weekend to see some of them.
The talk was about Bayesian methods in health economics (the slides of the presentation are here). I thought it went well and people (most of whom, if not all, were pharmacologists) were kind enough to come and tell me after the talk that they've understood the basics of Bayesian analysis. I was deliberately vague with the technicalities, but hopefully they will have become interested in the approach and grasped some of the main points.
Apart from the conference, I was, again, impressed by the city, which I think is really beautiful. It's quite big as well (~1 million residents, I'm told), but it doesn't really feel that way; you can easily walk around the city center and enjoy the elegant buildings and chocolate shops (and no: I did not get money from the local tourist information office!).
What was really funny is that I had a strong realisation of being in Italy while we were taking a stroll on Saturday after dinner. Imagine something like this:

In fact, the picture is not us, or even Turin; but the point is that it was so familiar to see so many people walking around with no purpose at all, just for the sake of being seen and seeing other people, and the only possible distraction of an ice cream.
Wednesday 3 October 2012
Goldacre mine
During a quick break between meetings, I've watched Ben Goldacre's new TED lecture. I met Ben when he gave a talk at the final conference of the Evidence project (in which I was involved), back in 2007. I like him, particularly for his wild hair, a feature I hold dear, and I quite often agree with him on issues related to the use of evidence in medical studies. In this presentation, he talks about the problem with publication bias, which I think this is one of his pièces de résistance. In particular he discusses the severe bias in the publication of clinical trial results, where unfavourable outcomes tend to be swept under the rug.
Of course, this is a very relevant issue; to some extent (and I gather this is what Ben argues as well), only a clear and very strict regulation could possibly solve it. Typical examples that people consider is to establish a register of all authorised trials. In other words, the idea is to put all ongoing studies on an official registry, so that people can expect some results. Failure to publish results, either positive or negative, would then be clear evidence of the latter. [I'm not sure whether something like this does exist. But even in that case, I don't think it is enforced $-$ and Ben seems to suggest this too, in the talk].
The problem is that, probably, this would not be enough to magically solve the problems $-$ I can definitely see people trying hard to find loopholes in the regulation, eg classifying a trial as "preliminary" (or something) and therefore maintain the right of not publishing the results, if they so wish...
May be this is an indirect argument for being more openly Bayesian in designing and analysing clinical trials. For example, if some information is present on the level of ongoing research in a given area, may be one could try and formalise some measure of "strength" of the published evidence. Or even more simply, if some sceptical prior is used to account for the information provided by the literature, the inference would be less affected by publication bias (I think this is a point that Spiegelhater et al discuss a lot in their book).
Of course, this is a very relevant issue; to some extent (and I gather this is what Ben argues as well), only a clear and very strict regulation could possibly solve it. Typical examples that people consider is to establish a register of all authorised trials. In other words, the idea is to put all ongoing studies on an official registry, so that people can expect some results. Failure to publish results, either positive or negative, would then be clear evidence of the latter. [I'm not sure whether something like this does exist. But even in that case, I don't think it is enforced $-$ and Ben seems to suggest this too, in the talk].
The problem is that, probably, this would not be enough to magically solve the problems $-$ I can definitely see people trying hard to find loopholes in the regulation, eg classifying a trial as "preliminary" (or something) and therefore maintain the right of not publishing the results, if they so wish...
May be this is an indirect argument for being more openly Bayesian in designing and analysing clinical trials. For example, if some information is present on the level of ongoing research in a given area, may be one could try and formalise some measure of "strength" of the published evidence. Or even more simply, if some sceptical prior is used to account for the information provided by the literature, the inference would be less affected by publication bias (I think this is a point that Spiegelhater et al discuss a lot in their book).
Monday 1 October 2012
Ordinal football
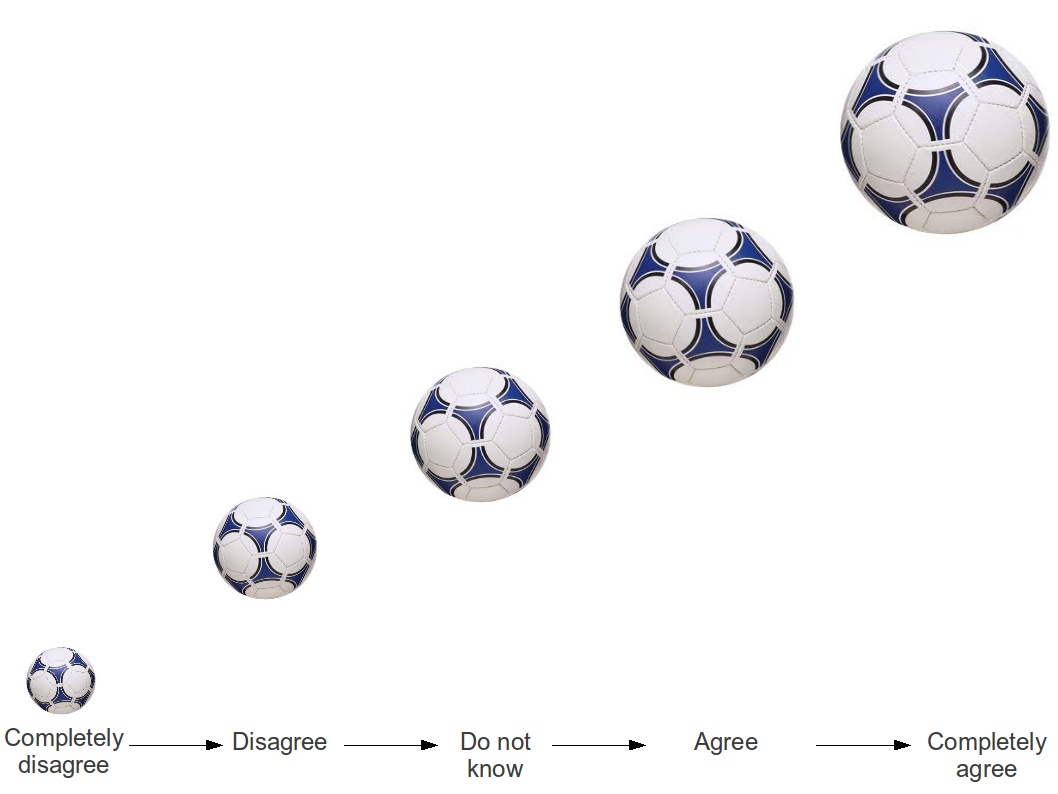
The main point of the post is that using ordinal regression models can improve the performance (I suppose in terms of prediction or validation of the probability associated with the observed frequency of the results).
At a very superficial level (since I've just read the article and have not thought about this a great deal), I think that assuming that the observed number of goals can be considered as an ordinal variable, much as you would do for a Likert scale, is not quite the best option.
This assumption might not have a huge impact on the actual results of this model; just as for an ordinal variable, the distance between the modalities is not linear (thus moving from scoring 0 to scoring 1 goal does not necessarily take the same effort required for moving from scoring 3 to scoring 4 goals). And ordinal regression can accommodate this situation. But I think this formulation is unnecessarily complicated and a bit confusing.
Moreover (and far more importantly, I think), if I understand it correctly, both the original models and those discussed in the post I'm considering seem to assume independence between the goals scored by the two teams competing in a single game. This is not realistic, I think, as we proved in our paper (of course drawing on other good examples in the literature).
In particular, we were considering a hierarchical structure in which the goals scored by the two competing teams are conditionally independent given a set of parameters (accounting for defence and attack, and home advantage); but because these were given exchangeable priors, correlation would be implied in the responses $-$ something like this:

The Bayesian machinery was very good at prediction, especially after we considered a slightly more complex structure in which we included information on each team's propensity to be "good", "average", or "poor". This helped avoid overshrinkage in the estimations and we did quite well.
An interesting point of the models discussed in the posts at R-bloggers is the introduction of a time effect (in this particular case to account for winter breaks in the Dutch league). In our experience, we have only considered the Italian, Spanish and English leagues (which, as far as I am aware of) do not have breaks.
But including external information is always good: for example, teams involved in European football (eg Champion's or Europa League) may do worse on the league games immediately before (and/or immediately after) their European fixture. This would be easy enough to include and could perhaps increase the precision in the estimations.
Subscribe to:
Posts (Atom)